728x90
반응형
cdQA-annotator는 node.js기반으로 squad(korquad) 데이터셋을 쉽게 만들어주는 도구이다.
github.com/cdqa-suite/cdQA-annotator
cdqa-suite/cdQA-annotator
⛔ [NOT MAINTAINED] A web-based annotator for closed-domain question answering datasets with SQuAD format. - cdqa-suite/cdQA-annotator
github.com
paragraphs안에 context와 question과 answer를 넣어서 json을 만들 필요 없이 context만 잘 정리해서 넣어주면 된다.
실험삼아 wikipedia dataset을 불러와서 csv로 저장한 후 python으로 json 형태로 만드는 작업을 진행하였다.
import pandas as pd
import json
data = pd.read_csv('./data/wiki.csv')
for i in range(len(data)):
squad_data={
"title": data['title'][i],
"paragraphs": [
{
"context": data['paragraphs1'][i],
"qas": []
},
{
"context": data['paragraphs2'][i],
"qas": []
}
]
}
with open('./data/wiki_make2.json','a') as outfile:
outfile.write(json.dumps(squad_data))
outfile.write(',')
outfile.close()
with open('./data/wiki_make2.json','r',encoding='utf-8') as outfile:
data = json.load(outfile)question 없이 json파일로 잘 생성된 것을 볼 수 있다.

이제 cdQA-annotator에 파일을 넣어보자

Upload를 누르게 되면 이와 같은 페이지가 나오고 질문을 입력하고 해당하는 답변을 드래그 한 후 Add annotation을 누르게 되면 질문과 답변 형식으로 들어가게 된다.
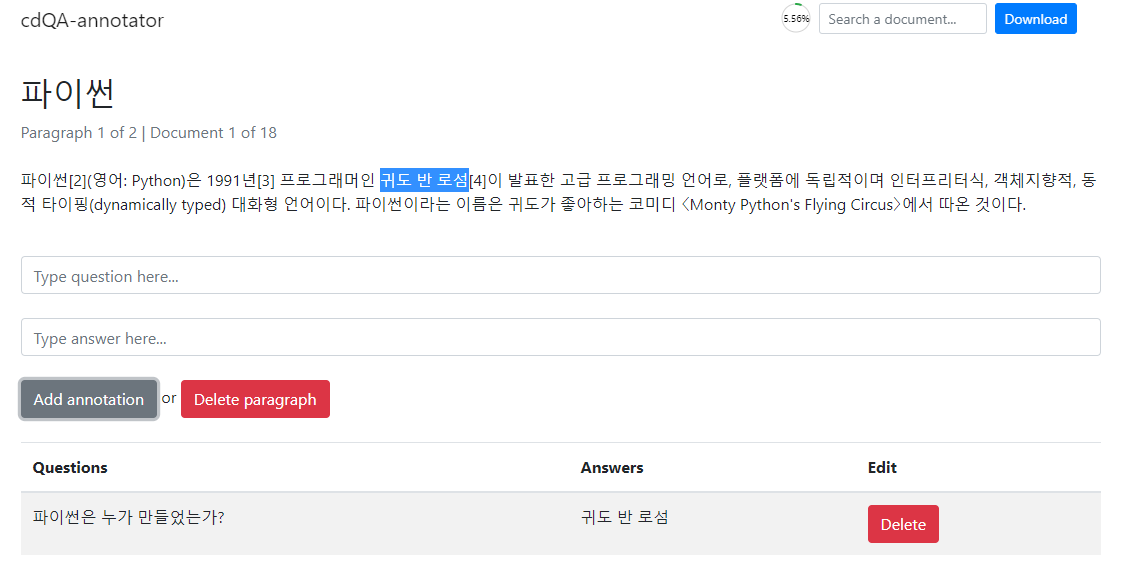
모든 context에 이와 같은 작업을 진행한 후 완전한 KorQuAD 파일을 json형식으로 내려받을 수 있다.
728x90
반응형
'Data > 자연어 처리' 카테고리의 다른 글
| LLM(Large Language Model) 기본 정리 및 활용 방안 | LIM (0) | 2024.03.17 |
|---|---|
| Keyword Extract using KeyBERT (1) | 2020.12.29 |
| TextRank를 이용하여 핵심 문장 추출하기 (1) | 2020.12.28 |
| GPT2 에서 문장을 생성 시 단어를 확률에 따라 선택하는 방법 (0) | 2020.12.15 |
| Question Generation (0) | 2020.12.10 |



댓글