빅쿼리에는 Array와 Struct로 데이터를 관리하고 조회할 수 있다.
ARRAY
데이터 유형이 동일한 값으로 구성된 목록을 ARRAY 라 부른다. 하나의 행에 데이터 타입이 동일한 여러 값이 저장된다.
아래에서 details.unique_key 는 배열로 구성된 부분이다. 빅쿼리에서 ARRAY를 보여줄 때 세로로 나열된다.

STRUCT
STRUCT 는 STRUCTURE의 줄임 표현이다. 처음에 이해할 때는 Python의 Dict와 유사한 느낌이라고 이해하면 편하다.
Python에서 Dict in List, List in Dict 가 가능한 것처럼 빅쿼리에서도 Struct in Array, Array in Struct 가 가능하다.
빅쿼리에서 STRUCT를 보여줄 때 가로로 나열된다.

실제로 적용해보기
참고한 데이터셋: bigquery-public-data.chicago_taxi_trips.taxi_trips
빅쿼리에서는 STRUCT를 활용해 여러 개의 필드를 하나의 필드에 정리할 수 있다.
Bigquery Public Dataset 인 chicago_taxi data로 테스트를 해보았다.
아래는 기존 table schema이다.
STRUCT로 묶을 수 있는 column 들을 나눠보았다.

1. STRUCT 로 묶고 싶은 칼럼들을 하나의 Field로 매핑한다.
ex. fare, tips, tolls, extras, trip_total, payment_type => cost(payment)
2. company, taxi_id, pickup_date를 기준으로 group by 하여 ARRAY 로 합친다.
CREATE OR REPLACE TABLE
`test.taxi_trips_new`
AS (
SELECT company, taxi_id, extract(date from trip_start_timestamp) as pickup_date,
ARRAY_AGG(
STRUCT(
unique_key,
trip_start_timestamp,
trip_end_timestamp,
trip_miles,
pickup_census_tract,
dropoff_census_tract,
pickup_community_area,
dropoff_community_area
)
) as details,
ARRAY_AGG(
STRUCT(
fare,
tips,
tolls,
extras,
trip_total,
payment_type
)
) as payment,
ARRAY_AGG(
STRUCT(
pickup_latitude,
pickup_longitude,
pickup_location,
dropoff_latitude,
dropoff_longitude,
dropoff_location
)
) as geographic
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` GROUP BY company, taxi_id, pickup_date
)참고) free tier 환경에서 테스트하시는 분들은 아마 전체 쿼리가 수행이 다 안되실 수 있습니다. 그럴 경우 pickup_date 를 조정해서 저장하면 됩니다. pickup_date(2023-01-01~2023-05-01)
기존 테이블과 Struct in Array로 변경했을 때 비교
기존(왼쪽)과 비교했을 때 Struct in Array로 변경되었을 때 용량도 줄어든 것을 확인할 수 있다. 거의 40%가 줄어들었다..!


기존에 데이터가 아래의 왼쪽 테이블처럼 저장되어 있었다면, struct와 array를 적용하고 나서 오른쪽처럼 변경되었기 때문이다.


데이터 스키마 확인해 보기
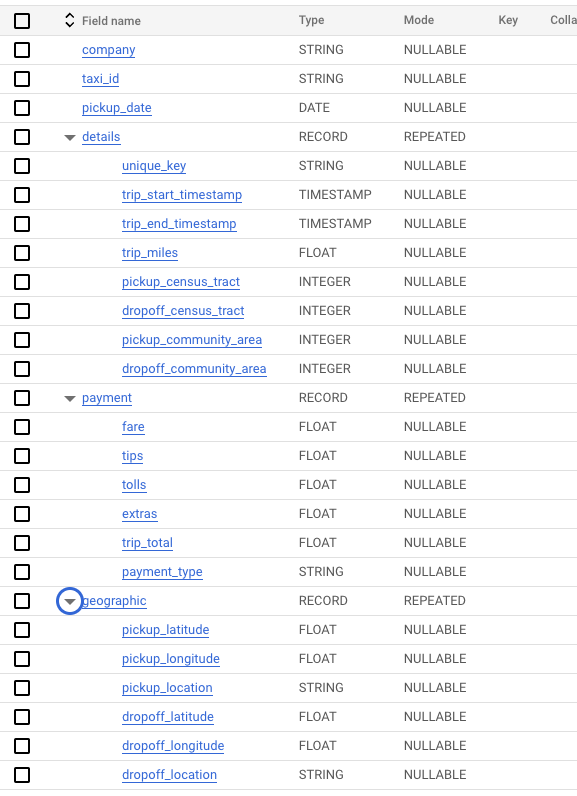
Type 이 Record이고 Mode 가 Repeated이다. 이건 데이터가 저장된 형태가 Struct in Array 이기 때문이다.
데이터 분석
데이터를 분석할 때는 UNNEST 를UNNEST를 이용하면 된다. 단순 Struct 형태라면 UNNEST를 이용하지 않아도 되지만
위 데이터 형태는 Struct in Array 이기 때문에 Unnest로 Array를 풀어줘야 그다음 Struct 형태로 쿼리 조회가 가능하다.
기존 테이블과 UNNEST를 단순 쉼표로 연결해서 데이터를 조회할 수 있다!
SELECT
taxi_id,
AVG(payment.fare) AS avg_fare
FROM
`test.taxi_trips_new`,
UNNEST(payment) AS payment
GROUP BY
taxi_id
📚 참고
https://zzsza.github.io/gcp/2020/04/12/bigquery-unnest-array-struct/
BigQuery UNNEST, ARRAY, STRUCT 사용 방법
BigQuery Unnest, Array, Struct 사용 방법에 대해 작성한 글입니다 목차 들어가며 BigQuery ARRAY BigQuery STRUCT BigQuery UNNEST 응용 정리
zzsza.github.io
Save Time and Money in BigQuery by Using Arrays and Structs
Learn to embrace and understand the nested schema
towardsdatascience.com
'Cloud' 카테고리의 다른 글
| [BigQuery] Streaming Buffer 란 무엇이고 왜 사용하는지 | LIM (0) | 2023.06.11 |
|---|---|
| [BigQuery] Surrogate key를 활용하여 JOIN 성능 높이기 | LIM (0) | 2023.06.09 |
| [GCP] BigQuery 란 무엇이며 생겨나게 된 배경 알아보기 | LIM (0) | 2023.05.21 |
| [BigQuery] Partition 과 Cluster 에 대해 알아보고 적용하기 | LIM (0) | 2023.03.12 |
| [GCP] VM Instance SSH 접속 (feat. Pycharm) | LIM (0) | 2023.01.20 |




댓글